![[新機能] メタデータを管理する最も簡単で最速な方法、Amazon S3 メタデータ (プレビュー) を試す! #AWSreInvent](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1733264019/user-gen-eyecatch/nu9vmksdp4nkcyl3qnrf.png)
[新機能] メタデータを管理する最も簡単で最速な方法、Amazon S3 メタデータ (プレビュー) を試す! #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。Amazon S3バケットのクエリ可能なオブジェクトメタデータ(プレビュー版)が発表されました。S3バケット内のオブジェクトメタデータを自動的に生成し、効率的にクエリできるようになります。
Amazon S3 メタデータとは
Amazon S3は、数十億から数兆のオブジェクトを含む個別のバケットを作成できる大規模なストレージサービスです。この規模で特定の条件を満たすオブジェクトを見つけることが課題となっていました。
そこで、登場したのがAmazon S3 メタデータです。S3オブジェクトの追加や変更時に自動的にメタデータを生成し、Apache Icebergテーブルに保存します。Apache Icebergテーブルは、Amazon Athena、Amazon Redshift、Amazon QuickSight、Apache Sparkなどのツールを使用してメタデータを効率的にクエリできます。メタデータスキーマには、バケット名、オブジェクトキー、作成/変更時間、ストレージクラス、暗号化状態、タグ、ユーザーメタデータなど20以上の要素が含まれます。
Amazon S3 メタデータの仕組み
- S3バケットのメタデータキャプチャを有効にします。
- メタデータの保存場所(S3テーブルバケットとテーブル名)を指定します。
- オブジェクトの作成、削除、メタデータの変更が数分以内にテーブルに反映されます。
Amazon S3 メタデータを試す
作成する方法は、AWSCLI(AWS API)とマネジメントコンソールがあります。当初は、AWSCLIを用いて作成を試みましたが執筆時点のAWSCLIコマンド(awscli-1.36.14とaws-cli/2.19.4)では、s3tablesサブコマンドが存在しなかったため、マネジメントコンソールで試します。また、今回はバージニア北部リージョン(us-east-1)で動作を確認します。
S3 bucketを作成
至って、普通にS3 bucket(cm-metadata-20241204)を作成します。
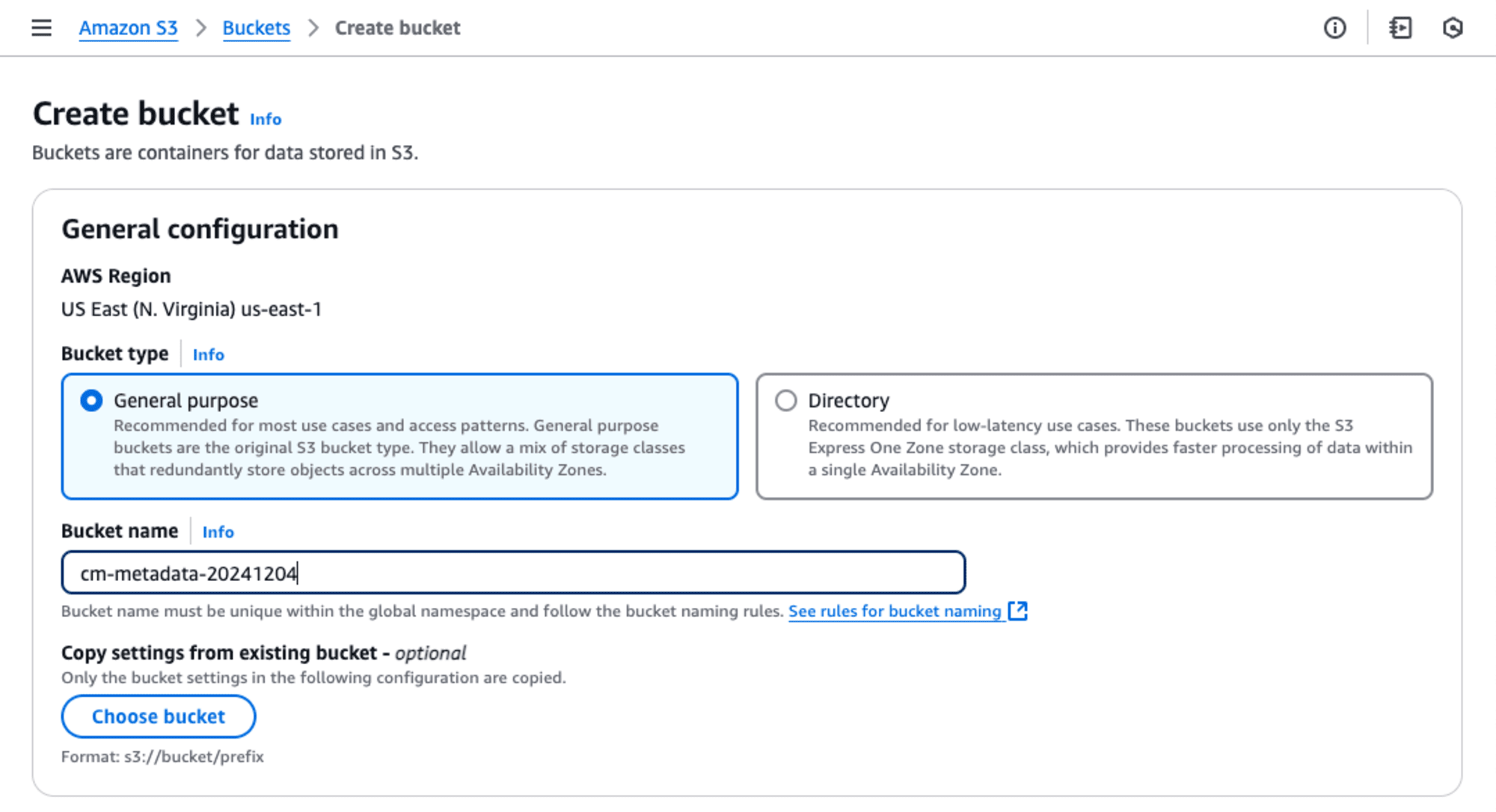
Table bucketを作成
左のメニューに新たに追加された[Table buckets New]を選択して、Table bucket nameに作成したS3 bucket(cm-metadata-20241204)を指定します。
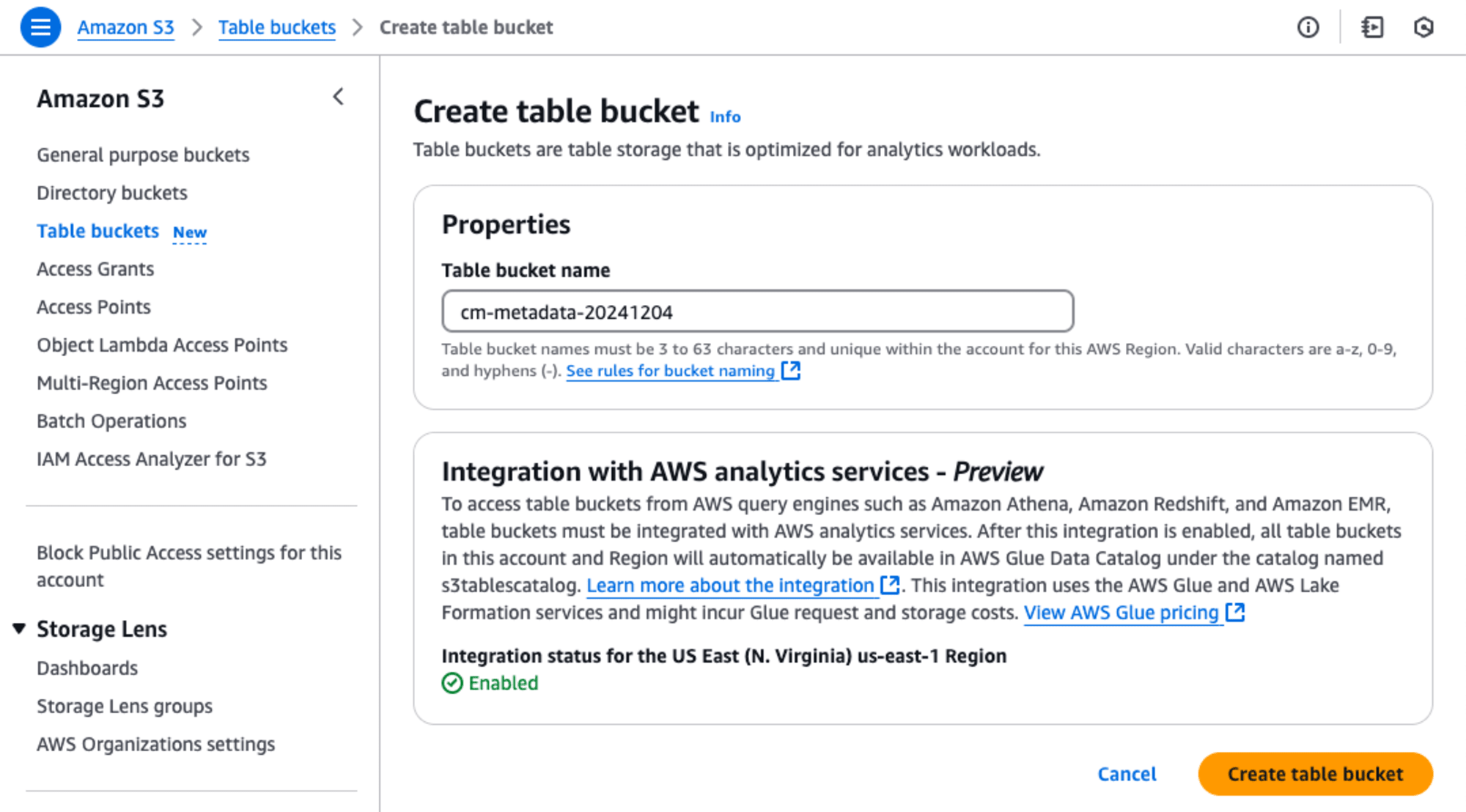
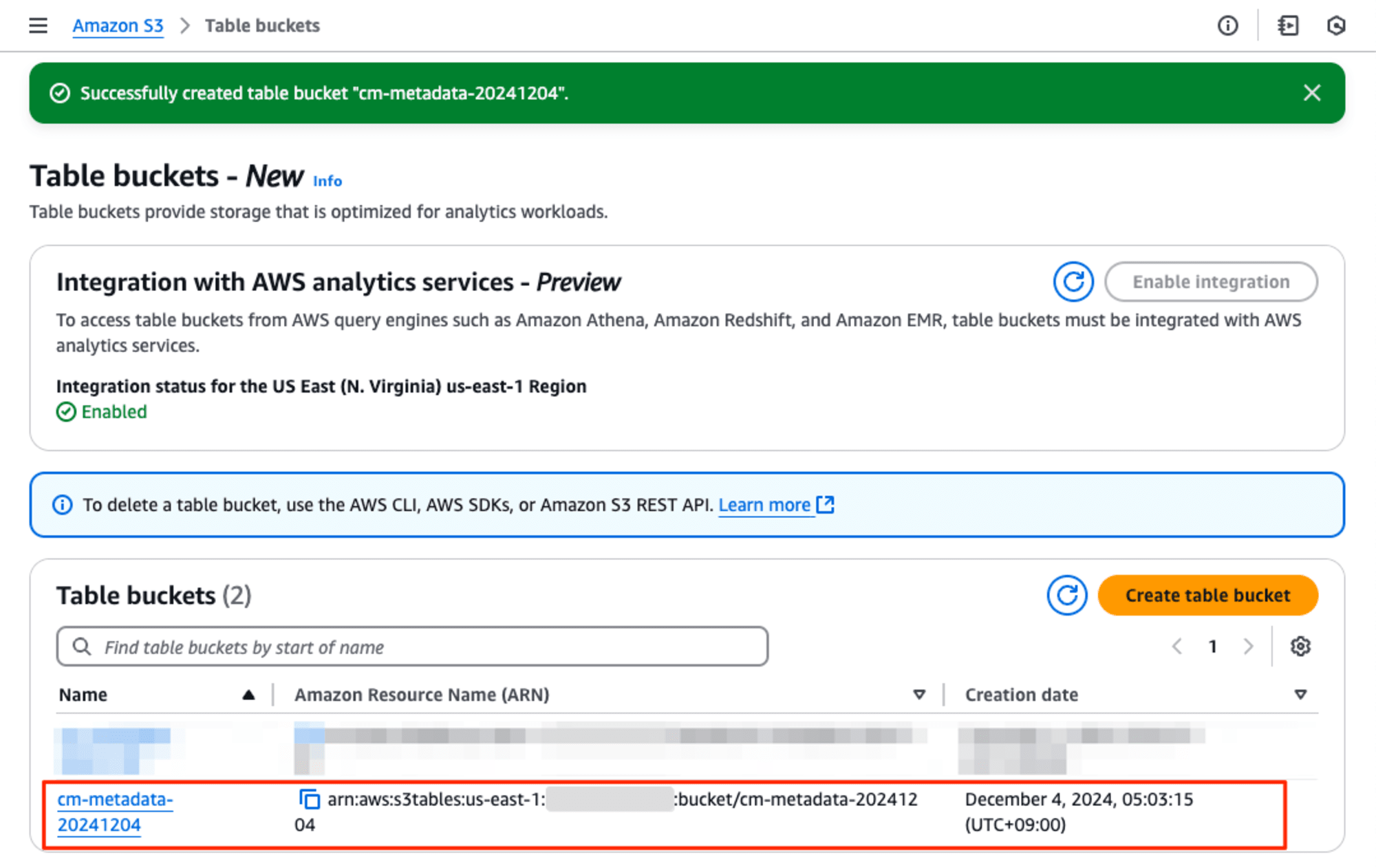
Table bucketが作成すると、そのAmazon Resource Name (ARN)は表示されます。
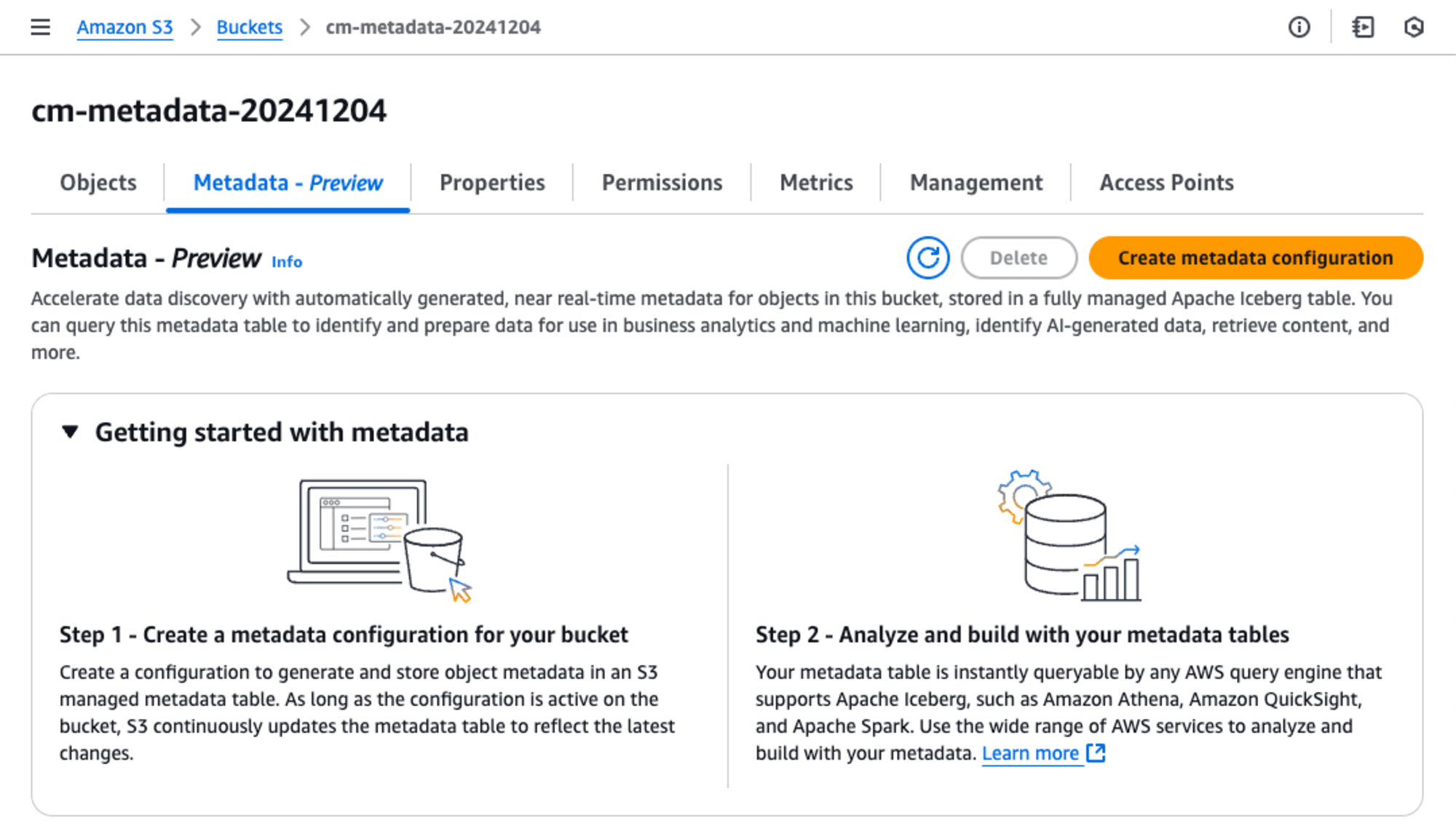
メタデータ設定を作成する
S3バケット(cm-metadata-20241204)の詳細を確認すると、[Metadata - Prewview]というタブが追加されています。、[Metadata - Prewview]タブを選択して、[Create metadata configuration]ボタンを押します。
先ほど作成したTable bucketのAmazon Resource Name (ARN)をDestination table bucket に入力します。Meta table name デフォルトで設定されていたので、そのままに[Create metadata configuration]ボタンを押して作成しました。
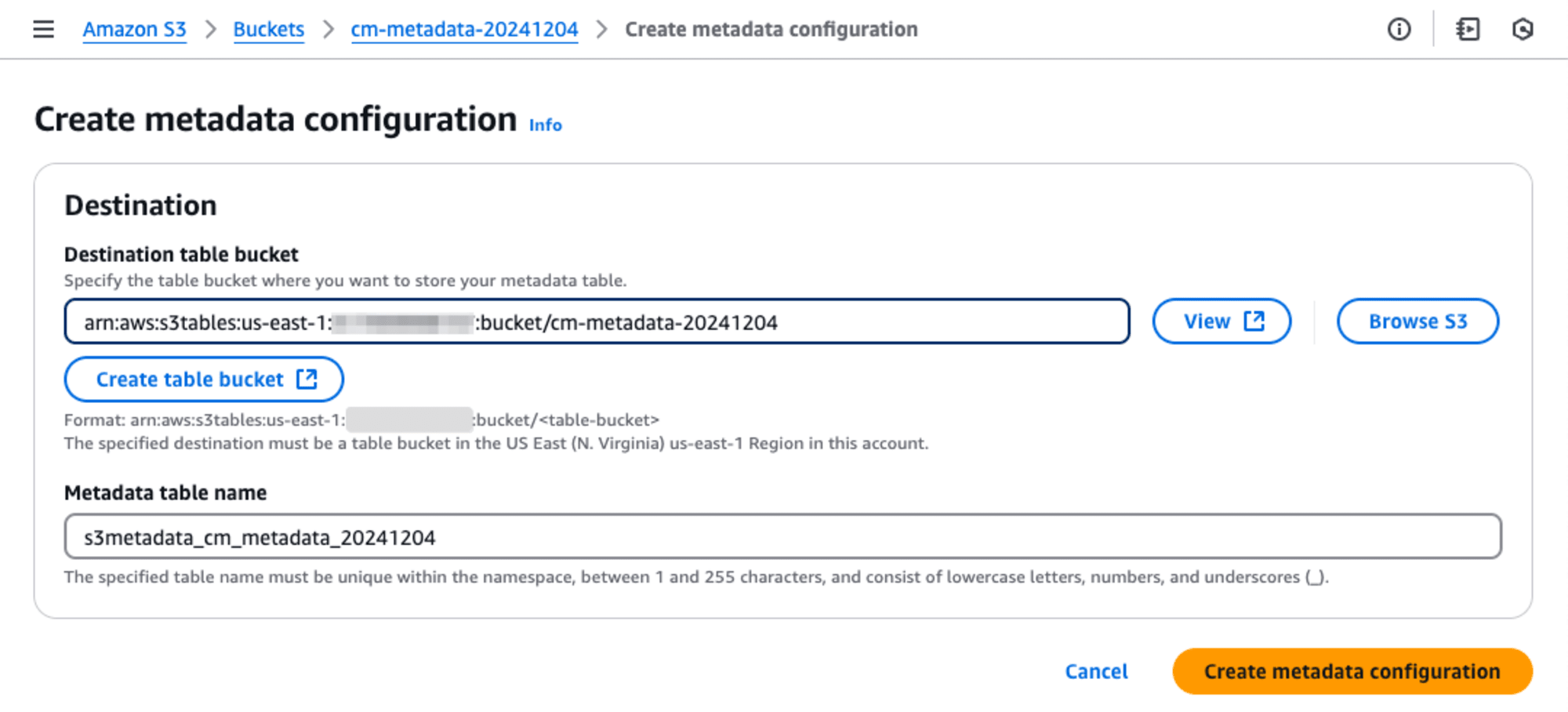
メタデータのテーブルの存在を確認する
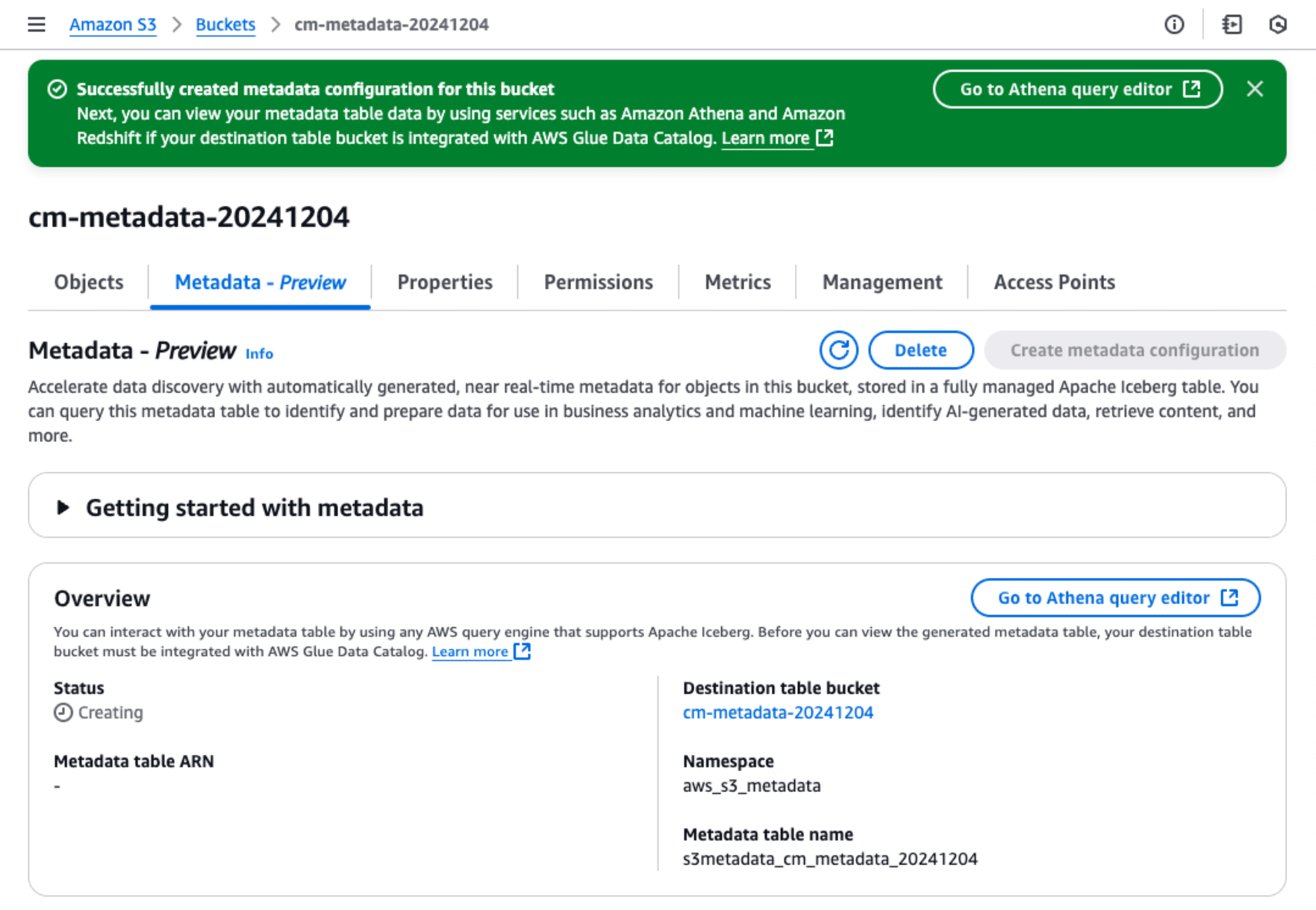
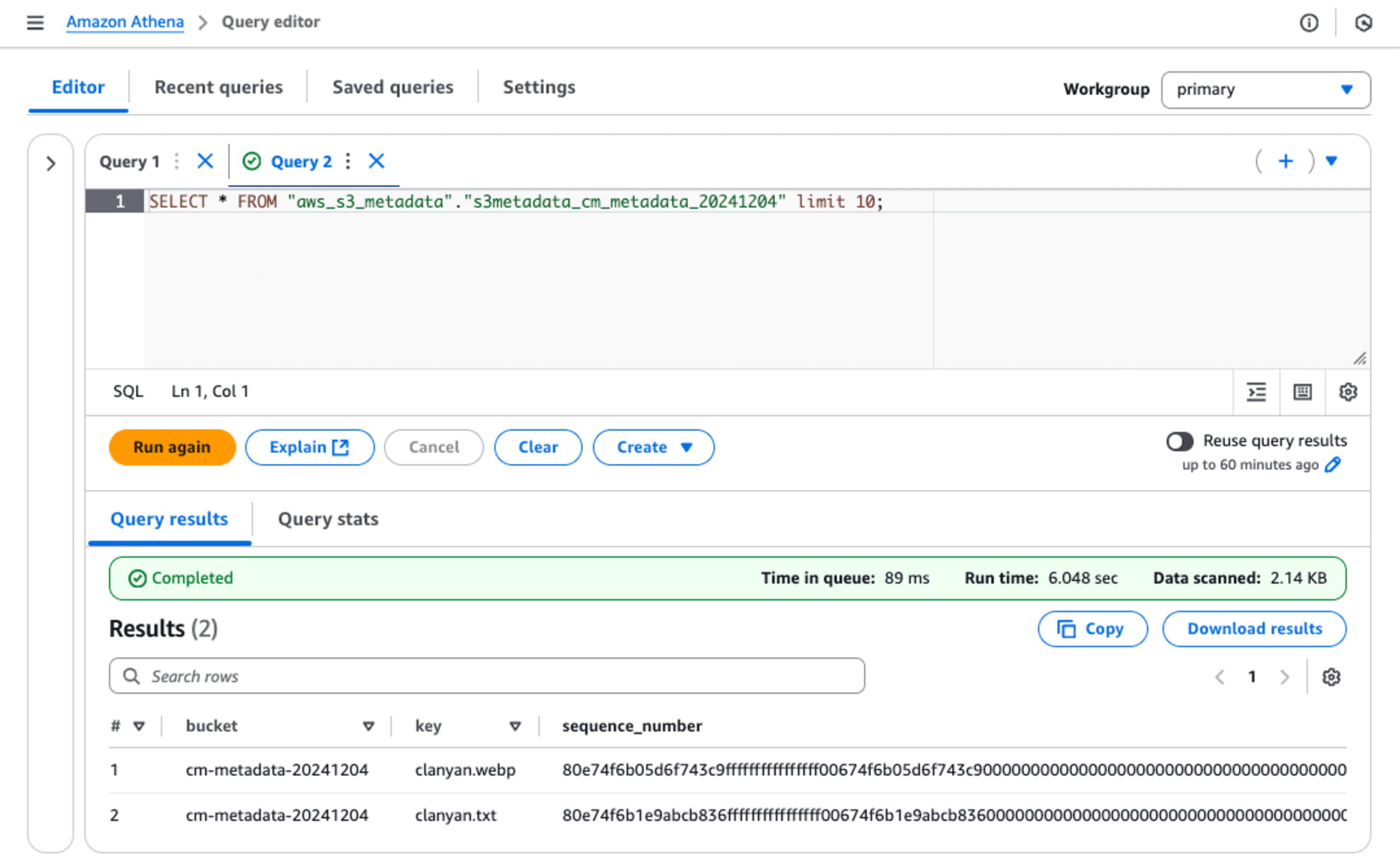
作成できると以下の画面が表示されます。これでメタデータを保存するテーブルも作成できたはずです。[Go to Athena query editor]ボタンを押して、Athenaで開いてみましょう
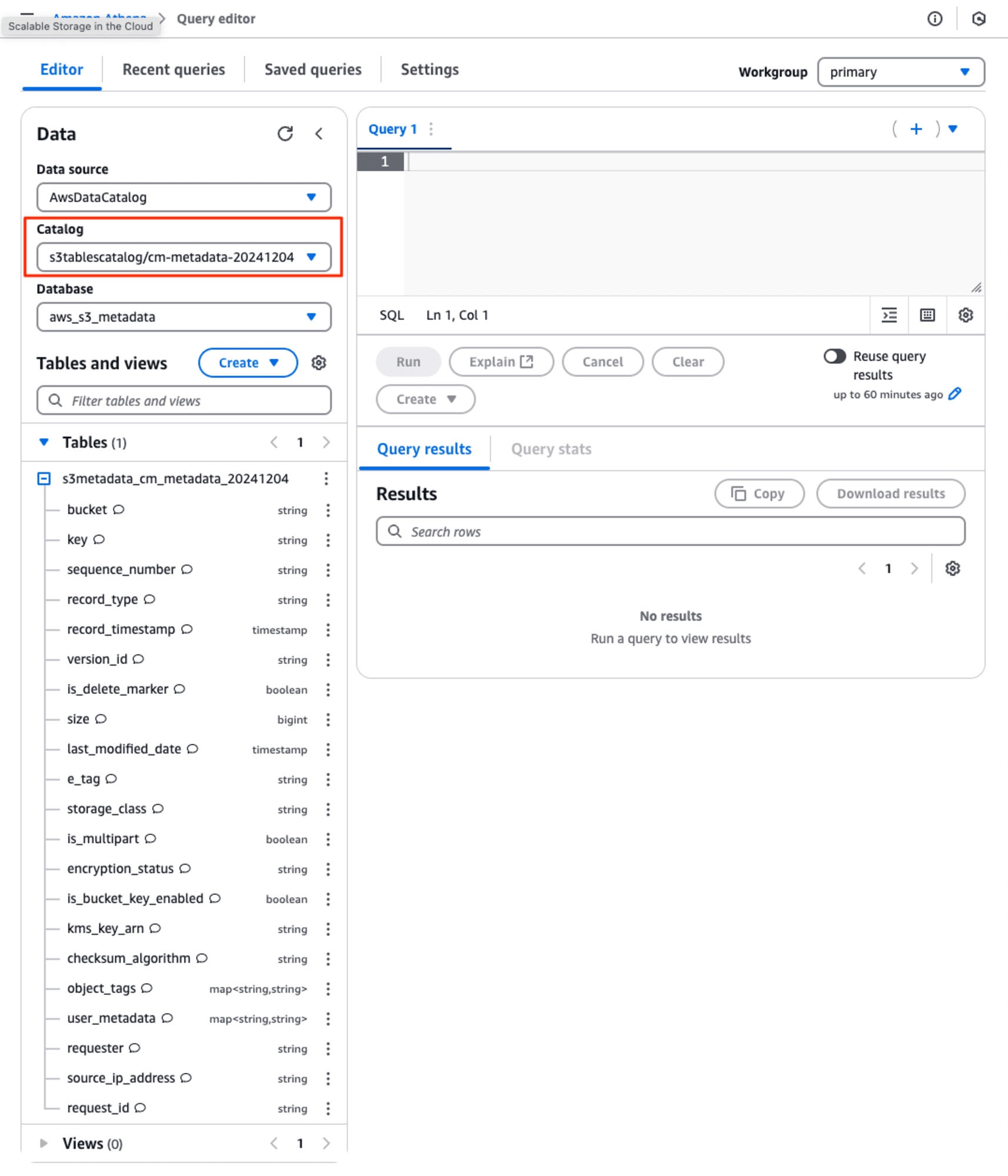
Amazon Athenaでメタデータのテーブル(s3metadata_cm_metadata_20241204)を確認します。Catalogというプルダウンが新たに追加されました。Catalogにs3tablecatalog/cm-metadata-20241204、Databaseにaws_s3_metadataを選択するとテーブルが確認できます。テーブルのスキーマに様々なメタ情報のカラムが存在します。
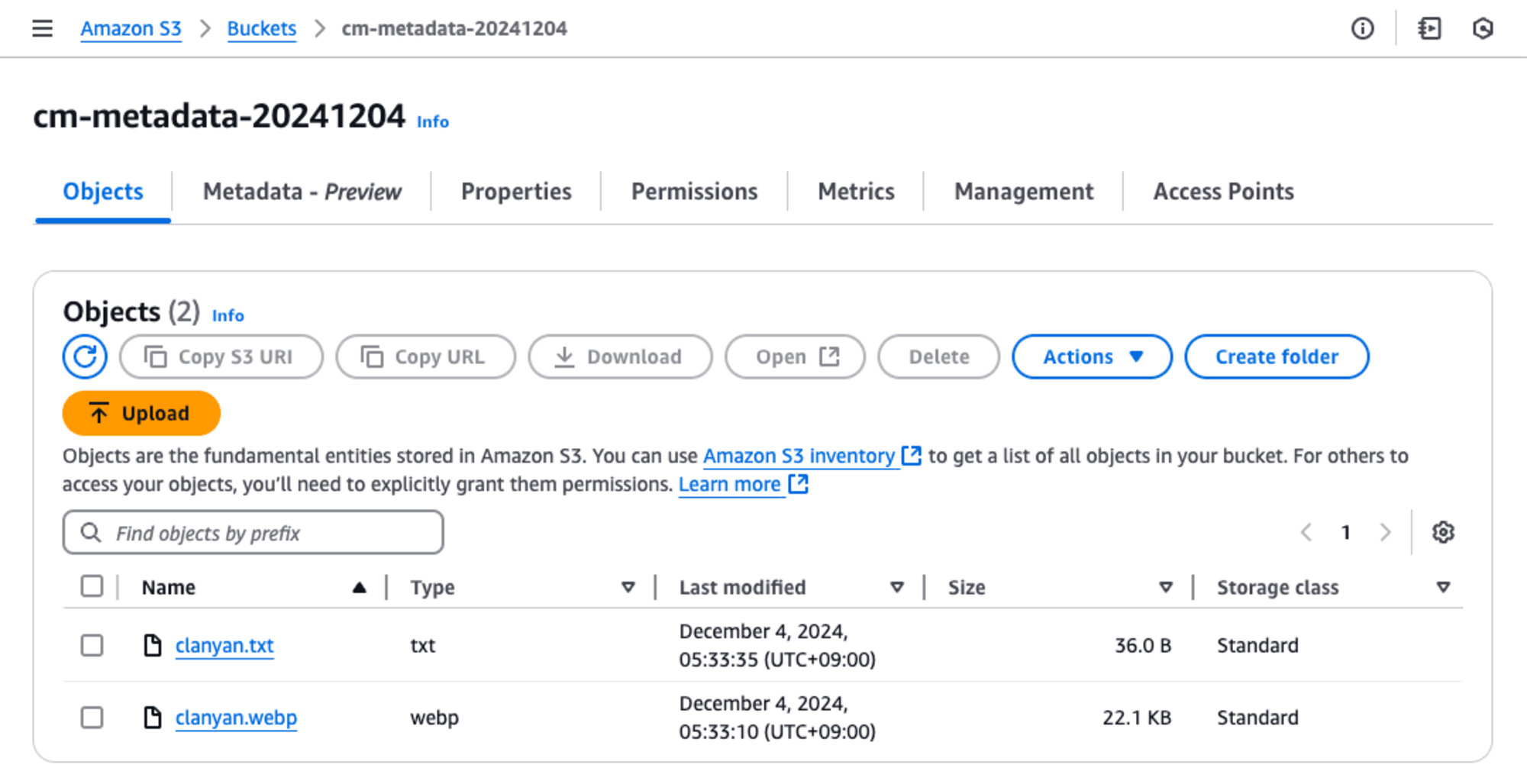
現状は、S3 Bucketに何もファイルをファイルを追加していないため、メタデータが追加されていません。そこで、clanyan.webpとclanyan.txtという2つのファイルを順番にS3 Bucketへアップロードしました。
メタデータのテーブルのレコードを確認する
S3 Bucketへファイルをアップロードして、数分経過しましたので中身を確認します。確認すると以下のエラーメッセージが表示されます。
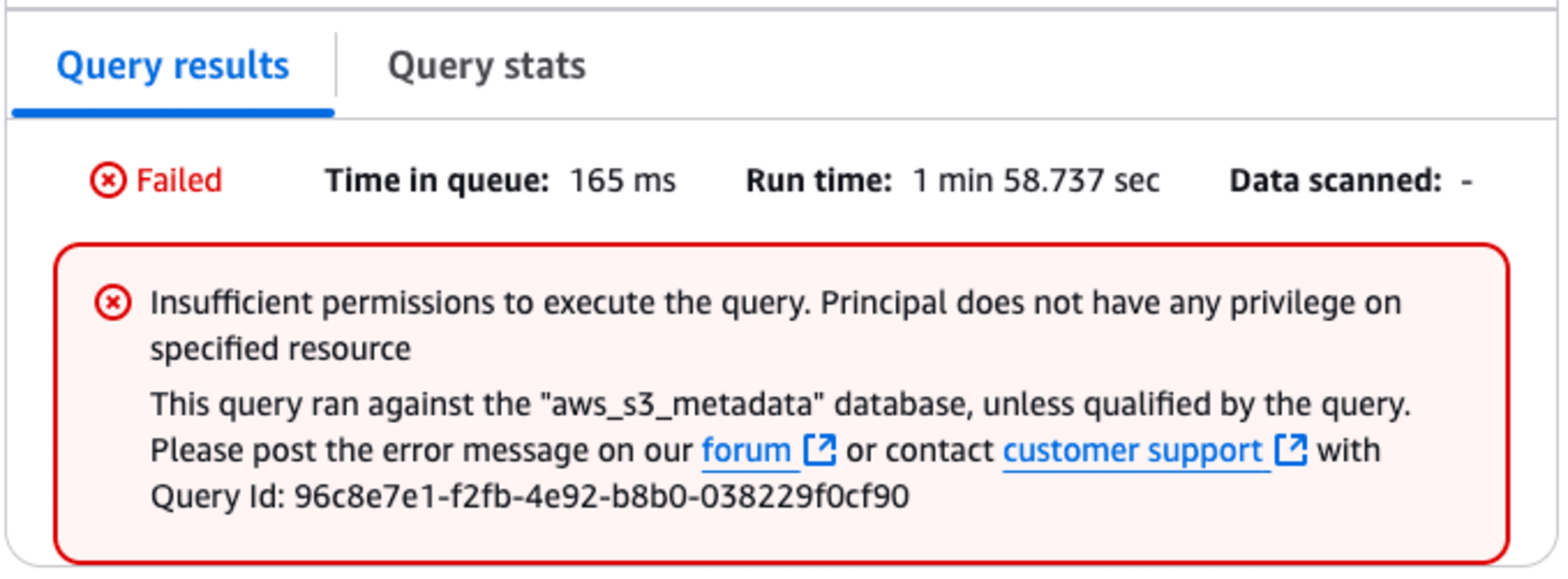
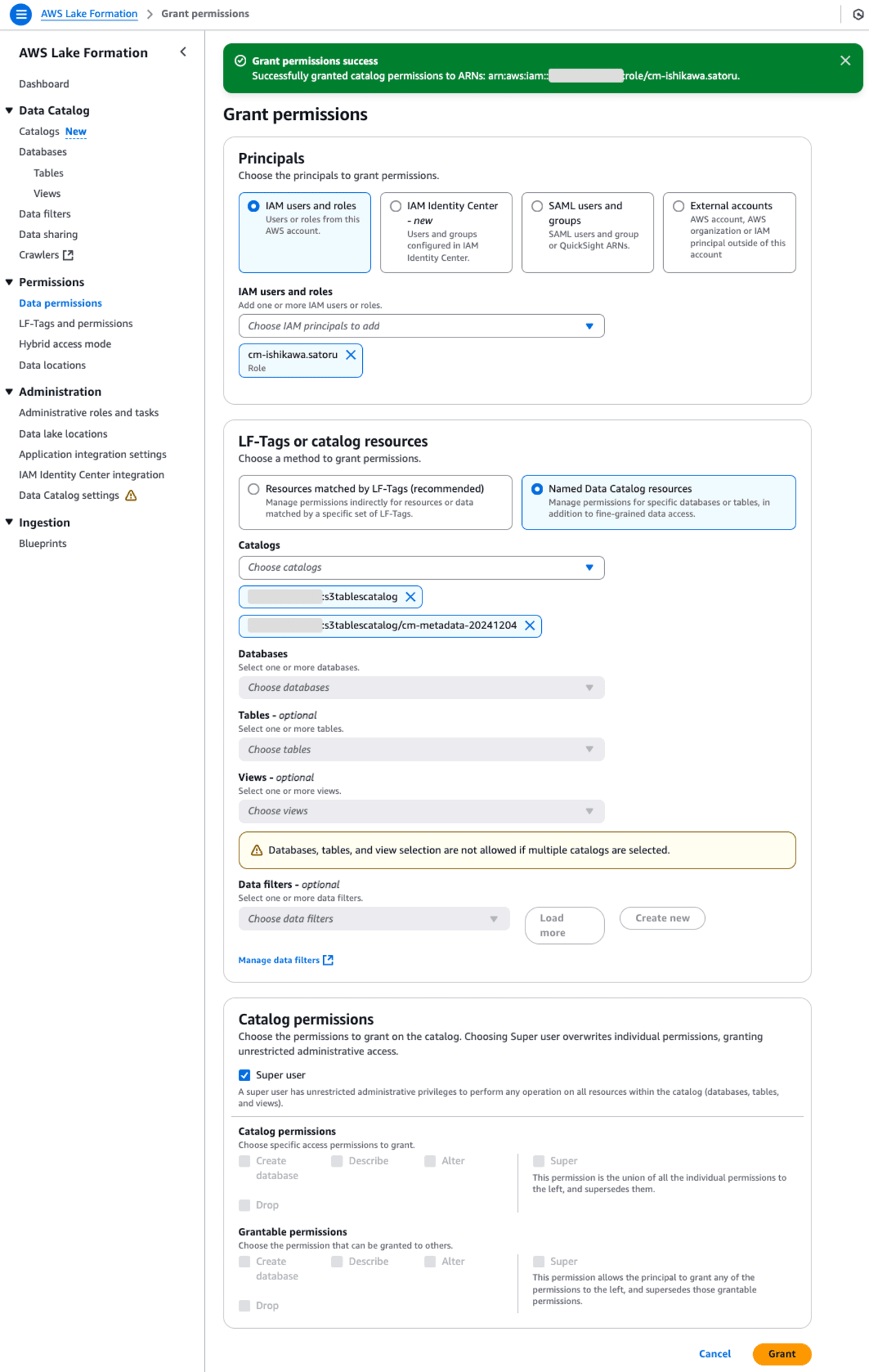
動物の勘を働かせ、Lake Formationを確認したところ、左に [catalogs New]というメニューが追加されていました。ここで、IAM users and rolesに自分を追加、、Catalogsはs3tablecatalogを追加、Catalog permissionsはSuper userを付与しました。
2つのファイルをアップロードしたイベントが登録されていました。
リージョンと料金
- 現在、米国東部(オハイオ、バージニア北部)と米国西部(オレゴン)のAWSリージョンでプレビュー版が利用可能です。
- AWS Glue Data Catalogとの統合もプレビュー中で、AWSアナリティクスサービスを使用してS3メタデータテーブルを含むデータのクエリと可視化が可能です。
- 価格設定は、更新(オブジェクトの作成、削除、メタデータの変更)の数と、メタデータテーブルの保存料金に基づいています。
最後に
Amazon S3メタデータ(プレビュー)は、S3バケット内のオブジェクトのメタデータを自動で管理する新機能です。この機能により、ユーザーは膨大な数のオブジェクトを含むS3バケット内で、特定の条件を満たすオブジェクトを効率的に見つけることが可能になります。
オブジェクトの追加や変更時に自動的にメタデータを生成し、Apache Icebergテーブルに保存することで、様々なAWSのアナリティクスツールを使用して簡単にクエリを実行できます。バケット名、オブジェクトキー、作成/変更時間、ストレージクラスなど、20以上の要素を含む豊富なメタデータスキーマにより、詳細な分析が可能になります。
現在はプレビュー版として一部のリージョンで利用可能であり、AWS Glue Data Catalogとの統合も進行中です。この新機能は、大規模なデータ管理や分析を行う企業にとって、データの可視性と活用性を大幅に向上させる強力なツールとなることが期待されます。
合わせて読みたい










